8 Ways Survey Research is Better with Organic Random Device Engagement
This is an excerpt from a recent academic paper written by Dr. David Rothschild, Economist at Microsoft Research & Dr. Tobias Konitzer, C.S.O. and co-founder of PredictWise.
Organic random device engagement (RDE) polling relies on advertising networks, or other portals on devices, to engage random people where they are. One of the most common versions of this is within advertising modules on smartphones, but it can easily be placed in gaming, virtual reality, etc.
Survey respondents are asked to participate in a poll in exchange for an incentive token that stays true to the philosophy of the app in which they are organically engaged. This method has a number of advantages:
1. Fast
RDE can be extremely fast. RDD takes days (and weeks in some cases). Using social networks (assisted crowdsourcing) can be done a little faster, but still lacks speed compared to RDE. Using online panels is comparable in speed, if you pay for extra respondents from a merged panel (online panels will charge extra to get respondents from other panels to increase speed).
2. Cost-effective
RDE is extremely inexpensive compared with other sampling 12 options. The major RDE providers, like Pollfish, Dalia or Tap Research, charge 10% the cost of RDD, 20% the cost of using assisted crowdsourcing, and 25% the cost of online panels.
3. Coverage is good and growing
Accuracy is good because coverage is good. And, while RDE is still behind RDD in coverage at this time, it will reach parity soon. Coverage is similar to social media-based assisted crowdsource polling and much better than with online panels. Online panels have a very small footprint, which also affects their ability to get depth in population.
4. Response rate is solid
Pollfish reports a reasonable response rate (much higher than RDD), conditional on being targeted for a poll (to completion of the survey, that is). Online panels have low sign-up rates and high drop out but do not post comparable response rates. Social media-based polling, in assisted crowdsourcing, is reliant on ads that suffer from a very low click-through.
5. Flexible
RDE is meant to be flexible with the growth of devices. It should provide a seamless experience across device types. RDD is stuck with telephones, by definition. And, RDD is subject to interviewer effects (albeit to a smaller extent than in-person surveys), meaning that tone of voice can influence considerations of the respondent, or trigger undesired interviewer respondent interactions, ultimately introducing measurement error. RDE, with its streamlined experience, is not subject to this kind of error. (Tucker 1983; West and Blom 2017)
6. Telemetry data
RDE is able to supplement collected attitudinal data with a rich array of para or telemetry data. As we know, people who answer surveys are fundamentally different than people who do not. As the progressive analytics shop, CIVIS has argued recently, a battery of nearly 30 additional demographic, attitudinal, and lifestyle questions that get at notions of social trust and cosmopolitanism is necessary to be able to weight and correct for all the ways in which survey respondents are unusual. As Konitzer, Eckman and Rothschild (2016) argue, telemetry data is a much more cost-effective (and unobtrusive) way to collect these variables. Home and work location, commuting or mobility patterns or the political makeup of one’s neighborhood or social network, derived from satellite-based (read: extremely accurate) longitudinal location-coordinate data predict demographic variables well, such as race and income. And, applications on the device can more accurately describe political traits prone to erroneous self-report, such as frequency of political discussion, political engagement or knowledge.
7. RDE will get stronger in the future
Penetration of devices will further increase in the future, increasing reach of RDE in the US, and making RDE the only viable alternatives in less developed markets. But the rosy future for RDE is not just about penetration. Advances in bridging Ad IDs with other known identifiers in the American market, such as voter file IDs, Experian Gold IDs, etc., mean that individual targeting based on financial history or credit card spending patterns will be possible. And, RDE will be able to adopt list-based polling, in which political survey firms poll directly from the voter file, large-scale administrative data detailing the turnout and registration history of 250,000,000 Americans.
8. River sampling is different, as devices are unknown
River sampling can either mean banner-ad based polling or engagement with respondents via legacy websites or similar places RDE recruits from. In contrast to RDE, devices are unknown to river samplers: River sampling usually does not have access to the Ad ID, introducing two huge disadvantages: River samples have no way to address SUMA it is possible for fraudsters to engage with the same poll twice to increase chances to win the price for participation, especially if it comes in the form of financial incentives. And, any degree of demographic/geographic (not to mention individual) targeting is virtually impossible. In addition, banner ads themselves, similar to social-media ads, suffer from disastrous response rates. Good RDE polling is done with the cooperation of the publisher, providing a native experience, while banners ads are pushed through the ad-network. This degraded user experience depresses response rates and can introduce serious measurement error.
Second, ad-networks optimize their delivery in a way that fights against the random sample. The users are chosen because they are more likely to respond, due to unobserved variables (at least to the survey researcher), that are correlated with how they will respond. As this underlying data is never shared, it is impossible to correct for by the survey researcher.
However, just like every other modern online survey sampling method (RDD, assisted crowdsourcing, online panels), RDE relies on non-probability sampling. There is no sample method (anymore) that has perfect coverage and known probabilities for any respondent. This is one of the reasons we have developed analytics to overcome known biases. And, RDE has bias that we understand and can overcome, and additional data points that add to the power of correcting bias, such as telemetry data that is not available to RDD. While RDD has shifting and shrinking coverage, online panels suffer from panel fatigue and panel conditioning, and assisted crowdsourcing has survey bias introduced by efficient but to the polling firm nontransparent targeting algorithms that cannot be addressed, RDE is our method of choice, and the future, in the ever-changing market of polling.
Examples of RDE
Here we review work published in both Goel, Obeng and Rothschild (2015) and Konitzer, Corbett-Davies and Rothschild (N.d.) to showcase how effective RDE samples can be. And, add examples from the 2017-2018 special congressional elections.
Example 1:
(Goel, Obeng and Rothschild 2015) shows how RDE, through Pollfish, is able to closely match gold-standard polling such as the General Social Survey. This gold-standard uses yet another method: house-calls. This is unaffordable for most research, so we have left it off of this paper, but it provides a useful benchmark.
Example 2:
(Konitzer, Corbett-Davies and Rothschild N.d.) shows how RDE, utilizing the Pollfish platform, is able to closely match RDD polling in the 2016 election (actually doing slightly better). This is an example of using RDE samples with an analytic method call Dynamic MRP. The analytics methods are detailed in their paper.
When (Konitzer, Corbett-Davies and Rothschild N.d.) quantifies their state-by-state errors, they show that their predictions based on a single poll are not significantly worse than the predictions from poll aggregators. They compare their state-by-state estimates against the actual outcome. Compared to poll aggregator Huffington Post Pollster, their Root Mean Squared Error (RMSE) is only slightly higher: 4.24 percentage points vs. 3.62 percentage points (for 50 states excluding DC).
When they focus on the 15 closest states, predictive accuracy is even higher. The RMSE is 2.89 percentage points, compared to 2.57 percentage points of Huffington Post Pollster. Overall, besides binary accuracy the RDE-based polling predictions also have a low error in the precise percentage value.
This is illustrated in Figure 1.
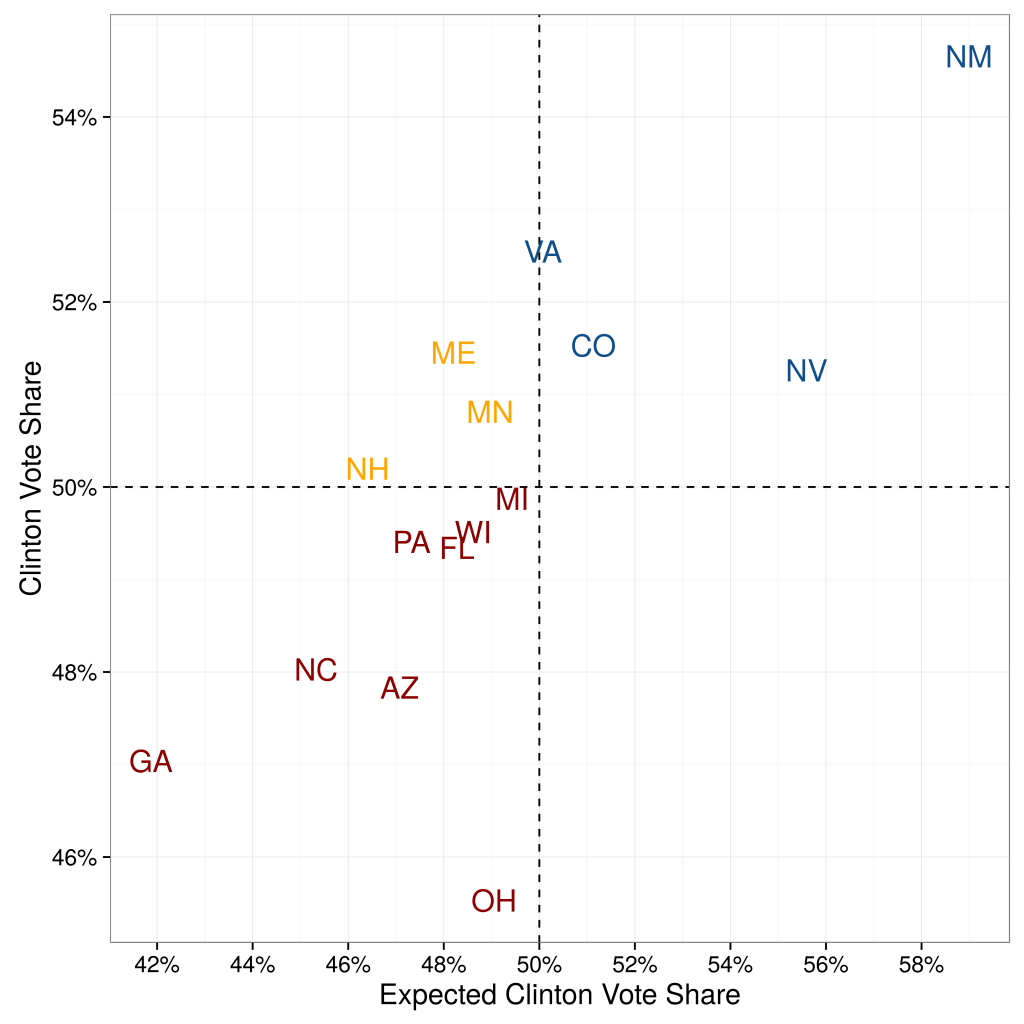
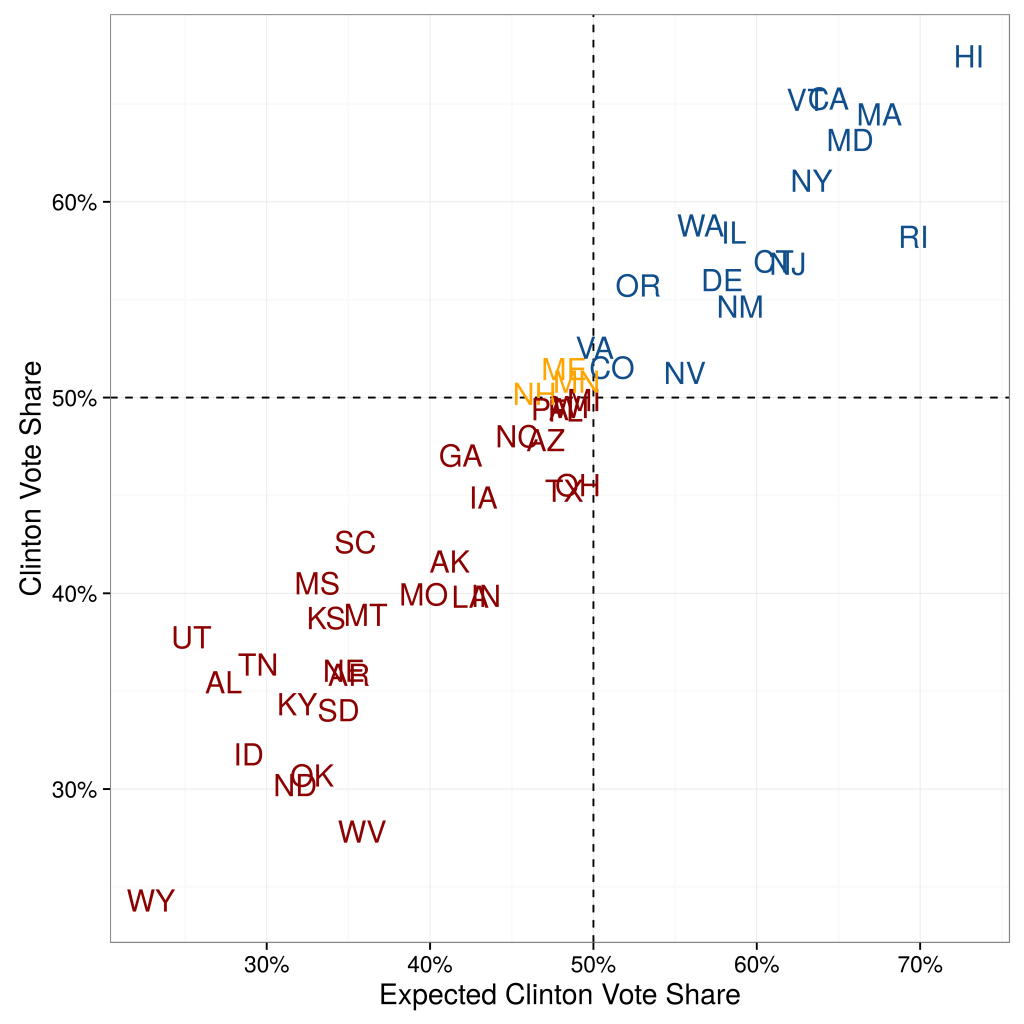
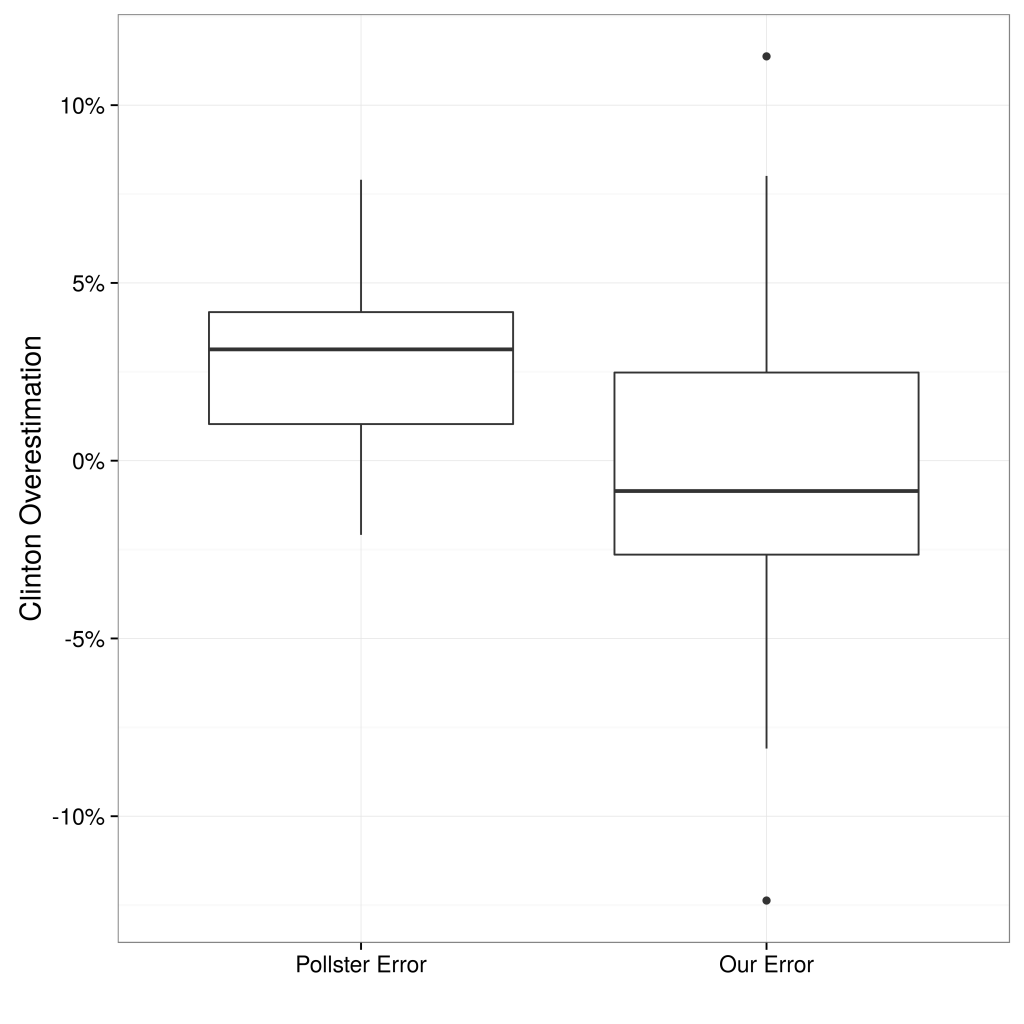
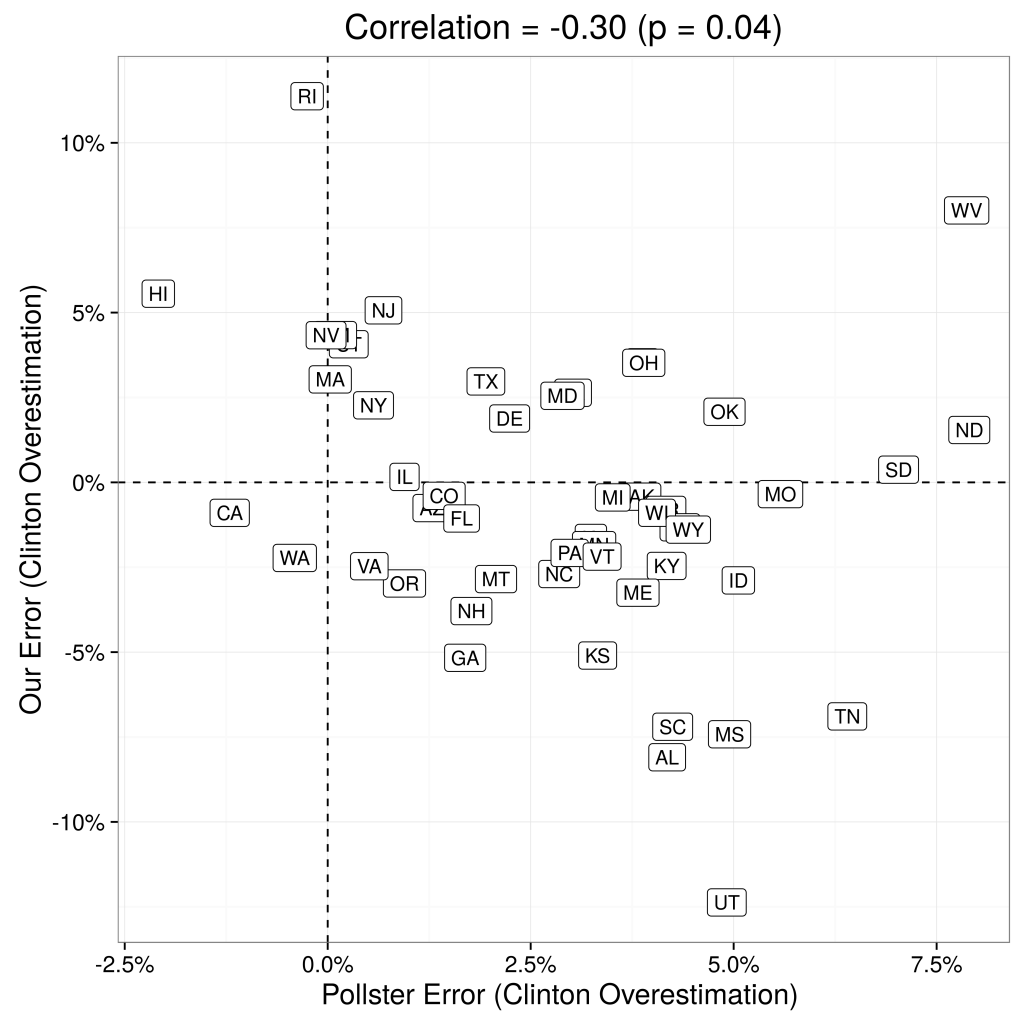
Not only are RDE-based polling state-by-state estimations fairly accurate, they also add meaningful signal to the poll aggregations. The left panel of Figure 2 displays the correlation between state-by-state errors of our predictions and the state-by-state errors of Huffington Post Pollster, and the right panel compares the distribution of errors across their approach and Huffington Post Pollster. At the very least, using RDE has significant potential to increase the quality of aggregators, as we discuss more below.
Example 3:
During the course of 2017 and 2018 polling firms have employed all three new methods in predicting Congressional election outcomes: RDE comes out way above the other two.
In this paper we outlined four methods of data collection for surveys. The first method, Random Digit Dialing (RDD), is the traditional method, working fine, but it is doomed in the next few years. Thus, the paper is really about which of the new online survey sampling methods will replace it: online panels, Assisted Crowdsourcing, or Random Device Engagment (RDE). We believe strongly that RDE is the future.
REFERENCES
Eckles, Dean, Brett R Gordon and Garrett A Johnson. 2018.
“Field studies of psychologically targeted ads face threats to internal validity.”
Proceedings of the National Academy of Sciences p. 201805363.
Gelman, Andrew, Sharad Goel, Douglas Rivers, David Rothschild et al. 2016.
“The mythical swing voter.”
Quarterly Journal of Political Science 11(1):103–130.
Goel, Sharad, Adam Obeng and David Rothschild. 2015.
“Non-representative surveys: Fast, cheap, and mostly accurate. In Working Paper.”
Halpern-Manners, Andrew, John Robert Warren and Florencia Torche. 2017.
“Panel Conditioning in the General Social Survey.”
Sociological Methods & Research
46(1):103–124. PMID: 28025587.
URL: https://doi.org/10.1177/0049124114532445
Kasprzyk, Daniel. 2005.
“Measurement error in household surveys: sources and measurement.”
Technical report Mathematica Policy Research.
Konitzer, Tobias, Sam Corbett-Davies and David Rothschild. N.d.
“NonRepresentative Surveys: Modes, Dynamics, Party, and Likely Voter Space.”
Forthcoming.
URL: http://researchdmr.com/Methods2016.pdf
Konitzer, Tobias, Stephanie Eckman and David Rothschild. 2016.
“Mobile as Survey Mode.”
Porter, Stephen R, Michael E Whitcomb and William H Weitzer. 2004.
“Multiple surveys of students and survey fatigue.”
New Directions for Institutional Research 2004(121):63–73.
Sturgis, Patrick, Nick Allum and Ian Brunton-Smith. 2009.
“Attitudes over time: The psychology of panel conditioning.”
Methodology of longitudinal surveys 113:126.